


Unlocking the Power of Retrieval-Augmented Generation (RAG) in AI

Retrieval-Augmented Generation (RAG) is an advanced method that elevates the precision and dependability of generative AI models through the integration of externally retrieved information. This approach addresses a crucial need in the field of natural language processing, where traditional large language models (LLMs) may lack specific or up-to-date knowledge required to generate accurate responses.
At its core, RAG works by combining both internal and external resources to provide context to generative AI models. This context is essential for improving the relevancy and quality of the generated outputs. By leveraging external data sources, RAG enables AI systems to access a wealth of information beyond their pre-existing knowledge base, making them more versatile and adaptable to a wider range of tasks.
How RAG works using Langchain using Streamlit (Step by Step Guide)
Retrieval-Augmented Generation (RAG) is a sophisticated technique that enhances the capabilities of large language models (LLMs) by incorporating external data sources to provide context and improve the accuracy of generated responses. Understanding how RAG works using Langchain involves a step-by-step guide to implementing this powerful approach. Let's explore the detailed process below:
- Setting up Python Environment: Set up a Python virtual environment to manage dependencies cleanly. Use
venvorvirtualenvfor this purpose:
$ python3 -m venv myenv
$ source myenv/bin/activate # For Linux/Mac
$ .\myenv\Scripts\activate # For Windows- Installing Required Packages: Install necessary Python packages using pip:
$ pip install streamlit pypdf langchain langchain-openai- Importing Required Libraries: Import necessary libraries in your Python script:
import os
import pathlib
import streamlit as st
from pypdf import PdfReader
from tempfile import NamedTemporaryFile
from langchain.docstore.document import Document
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
from langchain.chains.question_answering import load_qa_chain
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders.csv_loader import CSVLoader- Defining Helper Functions: Define helper functions to handle PDF and CSV files, convert document content to JSON, and prepare files for processing.
def convert_to_json(document_content):
"""
Convert document content to JSON format.
Args:
document_content (str): Content of the document.
Returns:
str: JSON formatted document content.
"""
messages = [
SystemMessage(
content=system_message
),
HumanMessage(
content=document_content
)
]
answer = chat.invoke(messages)
return answer.content
def prepare_files(files):
"""
Prepare files for processing by extracting their content.
Args:
files (list): List of uploaded files.
Returns:
str: Concatenated content of all files.
"""
document_content = ""
for file in files:
if file.type == 'application/pdf':
page_contents = handle_pdf_file(file)
elif file.type == 'text/csv':
page_contents = handle_csv_file(file)
else:
st.write('File type is not supported!')
document_content += "".join(page_contents)
return document_content
def handle_pdf_file(pdf_file):
"""
Handle PDF files by extracting text content from each page.
Args:
pdf_file (UploadedFile): Uploaded PDF file.
Returns:
list: List of text content extracted from each page.
"""
document_content = ''
with pdf_file as file:
pdf_reader = PdfReader(file)
page_contents = []
for page in pdf_reader.pages:
page_contents.append(page.extract_text())
document_content += "\n".join(page_contents)
return document_content
def handle_csv_file(csv_file):
"""
Handle CSV files by extracting content.
Args:
csv_file (UploadedFile): Uploaded CSV file.
Returns:
str: Concatenated content of all pages in the CSV file.
"""
with csv_file as file:
uploaded_file = file.read()
with NamedTemporaryFile(dir='.', suffix='.csv') as f:
f.write(uploaded_file)
f.flush()
loader = CSVLoader(file_path=f.name)
document_content = "".join([doc.page_content for doc in loader.load()])
return document_content- Creating Streamlit Interface: Create a Streamlit interface for users to upload PDF files, enter OpenAI API key, and input query.
st.set_page_config(page_title='AI PDF Chatbot', page_icon=None, layout="centered", initial_sidebar_state="auto", menu_items=None)
st.title("PDF Chatbot")
files = st.file_uploader("Upload PDF files:", accept_multiple_files=True, type=["csv", "pdf"])
openai_key = st.text_input("Enter your OpenAI API key:")
query = st.text_input("Enter your query for pdf data:")- Initializing OpenAI Chat and Embeddings: Initialize the OpenAI chat instance with your OpenAI API key, set up embeddings and also initialize text sppliter.
if openai_key:
os.environ["OPENAI_API_KEY"] = openai_key
chat = ChatOpenAI(model_name='gpt-3.5-turbo-0125', temperature=0)
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000, chunk_overlap=1000)- Handling User Inputs: Handle user inputs, including uploaded files, OpenAI API key, and query text.
if st.button("Get Answer to Query"):
if files and openai_key and query:
document_content = prepare_files(files)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000, chunk_overlap=1000)
chunks = text_splitter.split_text(document_content)
db = FAISS.from_texts(chunks, embeddings)
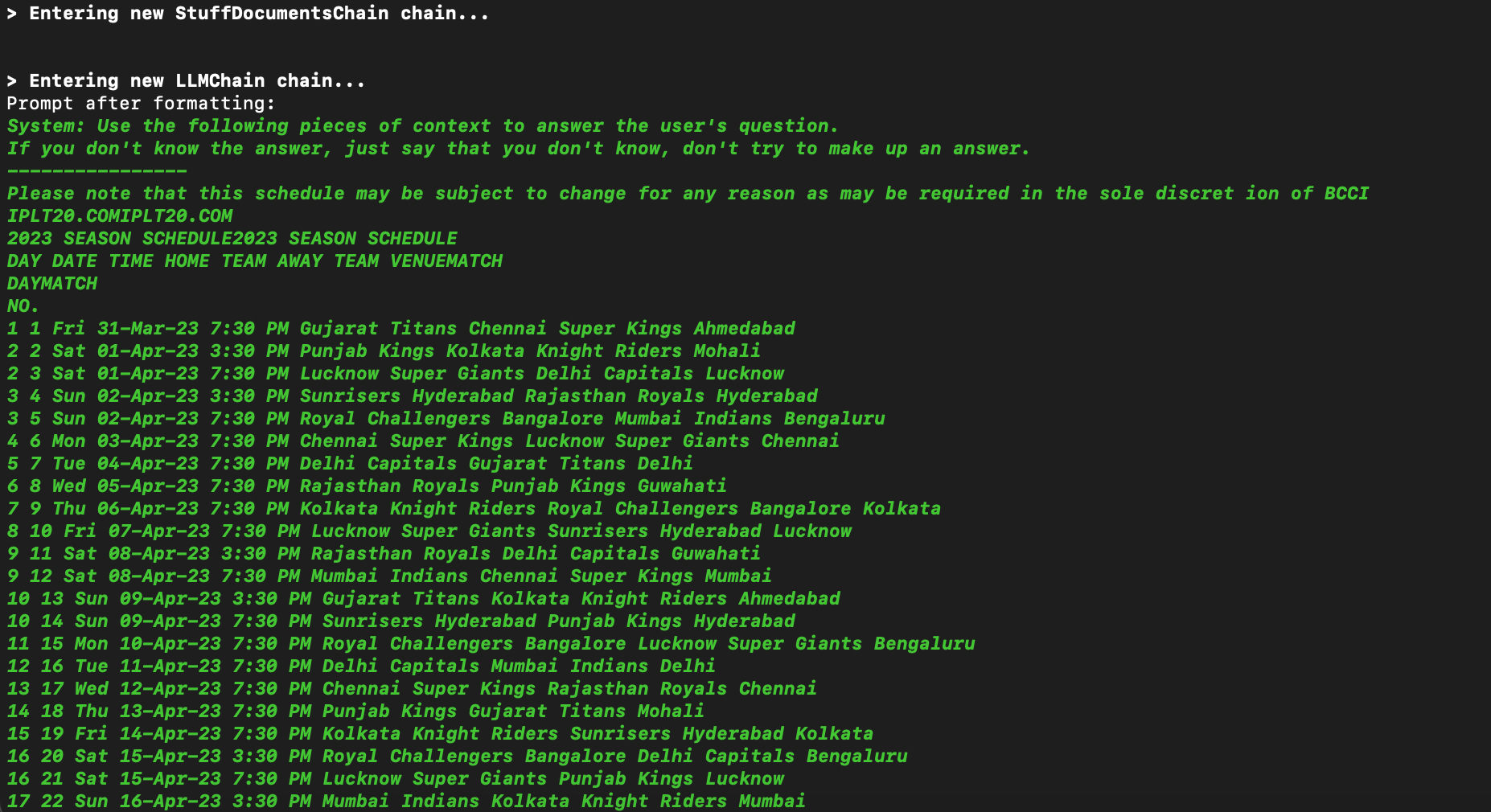
chain = load_qa_chain(chat, chain_type="stuff", verbose=True)
docs = db.similarity_search(query)
response = chain.run(input_documents=docs, question=query)
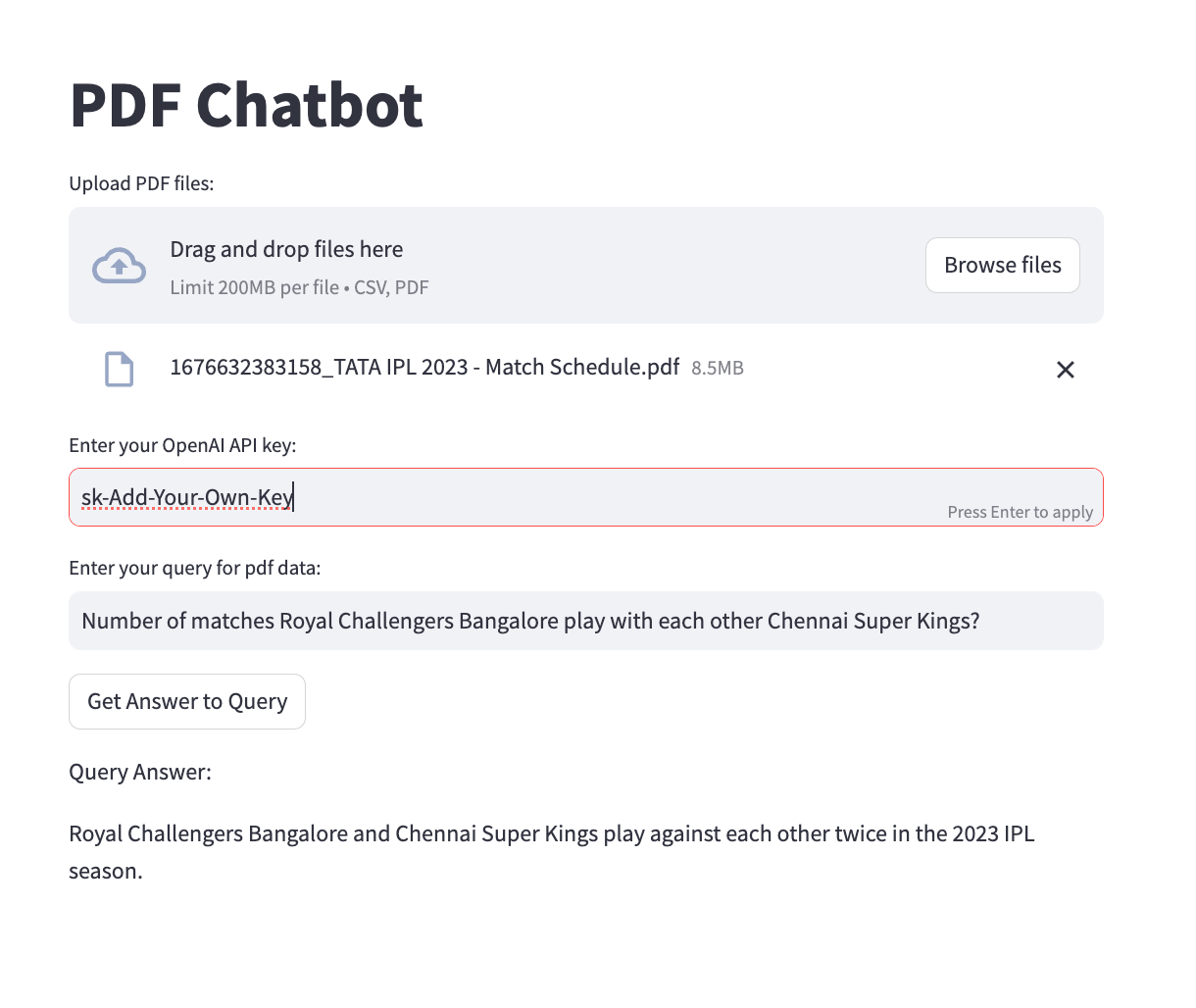
st.write("Query Answer:")
st.write(response)
else:
st.warning("Please upload PDF and CSV files, enter your OpenAI API key and query")- Retrieving Answers to Query: When the user clicks the button to get the answer to the query, process the uploaded files, split the text into chunks, perform similarity search, and retrieve the answer using the RAG model.
- Displaying Results: Display the retrieved answer to the user.
- Running Streamlit App: Finally, run the Streamlit application using the following command:
$ streamlit run pdf-to-trends.pyGitHub Repository for Above RAG Implementation
The source code for PDF-to-Trends is available on GitHub at langschain/pdf-to-trends. Feel free to explore the codebase, contribute to the project, or deploy your own instance of the application.
Applications of RAG in Various Industries
1. Healthcare Industry
In the healthcare sector, RAG plays a crucial role in improving patient care and diagnosis accuracy. AI models powered by RAG can access vast medical databases, research papers, and case studies to provide healthcare professionals with real-time, evidence-based information for making informed decisions. From assisting in medical image analysis to answering complex medical queries, RAG-enabled AI systems are transforming the way healthcare services are delivered.
2. Financial Services
Financial institutions benefit from RAG by leveraging external data sources to enhance fraud detection, risk assessment, and customer service. AI models equipped with RAG can analyze market trends, regulatory updates, and customer behavior patterns to offer personalized financial advice, detect anomalies in transactions, and ensure compliance with industry regulations. This leads to more efficient operations and improved decision-making processes in the financial services sector.
3. E-Commerce and Retail
In the e-commerce and retail industry, RAG is utilized to provide personalized product recommendations, optimize search results, and enhance customer support services. By accessing product reviews, inventory data, and customer feedback from external sources, AI-powered systems can offer tailored shopping experiences, address customer queries effectively, and improve overall customer satisfaction. RAG-driven AI models are reshaping the way businesses engage with their customers in the digital marketplace.
4. Education and Training
RAG is revolutionizing the education sector by enabling personalized learning experiences, automated grading systems, and interactive educational content. AI models integrated with RAG can access educational resources, research papers, and academic databases to offer students tailored study materials, instant feedback on assignments, and adaptive learning paths. This enhances the efficiency of educational processes and makes learning more engaging and effective for students.
5. Legal and Compliance
Legal firms and compliance departments benefit from RAG by automating legal research, contract analysis, and regulatory compliance tasks. AI systems powered by RAG can retrieve case law, legislative updates, and compliance guidelines from external sources to assist legal professionals in drafting legal documents, conducting due diligence, and ensuring regulatory adherence. By streamlining legal processes and providing accurate legal insights, RAG enhances the efficiency and effectiveness of legal operations.
6. Customer Service and Support
RAG is transforming customer service and support functions by enabling AI chatbots, virtual assistants, and helpdesk systems to provide accurate and personalized responses to customer queries. By linking AI models to external knowledge sources, RAG ensures that customer service representatives have access to the latest product information, troubleshooting guides, and company policies, thereby improving the quality of customer interactions and resolving issues more efficiently.
Challenges and Limitations of RAG
While Retrieval-Augmented Generation (RAG) offers a myriad of benefits and advancements in the realm of generative AI models, it also comes with its own set of challenges and limitations that need to be addressed. Understanding these hurdles is crucial for optimizing the implementation of RAG and overcoming potential obstacles in leveraging this innovative technique effectively.
- Challenges in Sourcing Data: Accessing high-quality and relevant external data sources is crucial for the effectiveness of RAG. However, maintaining a diverse pool of accurate information can be challenging, especially in domains with limited data accessibility or undefined quality standards.
- Privacy and Security Risks: Integrating external data raises significant privacy and security concerns. Protecting sensitive data from breaches and unauthorized access becomes paramount, especially in industries with stringent data privacy regulations.
- Interpretability and Explainability: Enhancing the interpretability of RAG-powered models is challenging due to their complexity. Ensuring transparency in decision-making processes is essential for building trust, yet achieving interpretability can be complex as models integrate external knowledge sources.
- Domain Adaptation and Generalization: Adapting RAG models to different domains and ensuring their generalization across tasks is challenging. While RAG enhances response relevance, fine-tuning models for varied contexts requires extensive training and optimization.
- Computational Resource Demands: Implementing RAG demands substantial computational resources, especially for processing large datasets and complex tasks. Balancing computational requirements with performance and scalability is crucial for optimal system functioning.
- Ethical Considerations and Bias Mitigation: Addressing ethical considerations and biases in RAG-generated outputs is critical. External data may perpetuate biases, necessitating proactive measures to promote fairness, inclusivity, and ethical use of AI.
- User Adoption and Acceptance: Convincing users of RAG's reliability and transparency is essential for adoption. Overcoming skepticism, addressing concerns about AI autonomy, and enhancing user experience require strategic communication and usability enhancements.
Future Prospects of RAG Technology
As the field of artificial intelligence continues to evolve, the future prospects of Retrieval-Augmented Generation (RAG) technology appear promising and transformative. With its ability to enhance the accuracy, reliability, and contextuality of generative AI models by integrating information from external sources, RAG is poised to revolutionize numerous industries and applications. Let's explore the potential future developments and advancements in RAG technology:
- Advancements in NLP: RAG technology will advance NLP by enriching AI-generated responses with external data, leading to more sophisticated conversational AI and advanced question-answering capabilities.
- Integration with Multi-Modal AI: RAG will play a crucial role in enhancing contextual understanding across modalities, enabling more comprehensive AI systems capable of delivering richer outputs in diverse formats.
- Expansion into New Verticals: RAG's benefits will drive adoption across industries like legal services, cybersecurity, and entertainment, enhancing decision-making and customer interactions.
- Enhanced Personalization: RAG-powered AI will provide more relevant and engaging content tailored to individual preferences, driving personalized recommendations and adaptive learning experiences.
- Ethical AI Practices: Future RAG developments will focus on addressing bias, transparency, and accountability, promoting responsible AI use and mitigating risks associated with biased outputs.
- Collaboration and Interoperability: RAG will foster collaboration and interoperability between AI systems and external data sources, enabling seamless integration and data sharing.
- Scalability and Efficiency: Improving scalability and efficiency of RAG-powered AI systems will be crucial for meeting growing demands, ensuring fast and reliable responses in real-time scenarios.
FAQ's
- What is Retrieval-Augmented Generation (RAG)?
RAG is a technique that improves the accuracy and reliability of large language models (LLMs) by allowing them to access and leverage information from external knowledge sources. - What is the role of RAG in generative AI?
Generative AI can sometimes struggle with factual accuracy. RAG acts as a fact-checker, providing LLMs with real-time access to reliable knowledge bases to ensure their responses are grounded in truth. - What is a RAG system?
A RAG system acts as a bridge between an LLM and a vast external knowledge base. When a user asks a question, RAG retrieves relevant information from this knowledge base and feeds it to the LLM, empowering it to generate more informed and accurate responses. - What is the RAG concept in AI?
The RAG concept focuses on boosting LLM confidence by providing them with the most recent information to tackle complex tasks and answer challenging questions effectively. - How is RAG different from an LLM?
LLMs are the core language processing engines, while RAG acts as a valuable research assistant. LLMs process information and generate text, and RAG helps them find the most relevant and up-to-date data to fuel their responses. They work together for better performance. - How does the retrieval process work in LangChain?
LangChain is a specific framework that implements RAG. Unlike a general search engine, LangChain retrieves information from a knowledge base tailored to the specific needs of the LLM within the LangChain system based on the user's query. - What's the difference between LangChain and RAG?
RAG is a broad concept for enhancing LLM performance with external knowledge. LangChain is a specific system built on RAG principles, focusing on tailored information retrieval for the LLM it works with. - What are the primary benefits of using RAG?
RAG offers a three-fold benefit:- Accuracy Boost: Ensures LLMs have access to reliable information for factually correct responses.
- Trustworthy Outputs: Users can trust LLM responses knowing they are grounded in verifiable sources.
- Domain Expertise: Enables integration with domain-specific knowledge bases for relevant responses in particular fields.
- How do you prepare data for RAG?
Data preparation for RAG involves two steps:- Training the LLM: The core LLM is still trained on massive amounts of text data, similar to traditional LLM training.
- Knowledge Base Curation: The external knowledge base needs to be structured and formatted for efficient retrieval of relevant information for the LLM's queries.
- What is a RAG model?
There's no such thing as a specific RAG model. It's an LLM that has been empowered by the RAG system. The LLM remains the core for processing information and generating text, while RAG acts as its information retrieval assistant, enhancing its capabilities.


