


Unlocking Insights from Complex PDFs: A Deep Dive into Unstructured.io

Businesses of all sizes grapple with the challenge of deriving value from vast amounts of unstructured data they accumulate. This data lacks organization for traditional analysis, making manual processing slow, error-prone, and often ineffective at revealing hidden insights crucial for business transformation. Moreover, handling diverse file formats and preparing and cleaning data further complicates the process, resulting in missed opportunities and competitive disadvantages.
Integrating Unstructured offers a powerful solution to these challenges. Unstructured specializes in simplifying the ingestion, comprehension, and preprocessing of unstructured data from multiple sources. This approach converts raw, disorderly data into well-structured assets, primed to uncover insights that drive innovation and business growth.
Setting Up Your Unstructured.io Environment:-
Installing the library
Use the following instructions to get up and running with unstructured and test your installation.
- Install the Python SDK to support all document types with
pip install "unstructured[all-docs]"- For plain text files, HTML, XML, JSON and Emails that do not require any extra dependencies, you can run
pip install unstructured - To process other doc types, you can install the extras required for those documents, such as
pip install "unstructured[docx,pptx]"
- For plain text files, HTML, XML, JSON and Emails that do not require any extra dependencies, you can run
- Install the following system dependencies if they are not already available on your system. Depending on what document types you're parsing, you may not need all of these.
libmagic-dev(filetype detection)poppler-utils(images and PDFs)tesseract-ocr(images and PDFs, installtesseract-langfor additional language support)libreoffice(MS Office docs)pandoc(EPUBs, RTFs and Open Office docs). Please note that to handle RTF files, you need version2.14.2or newer. Running eithermake install-pandocor./scripts/install-pandoc.shwill install the correct version for you.
- For suggestions on how to install on the Windows and to learn about dependencies for other features, see the installation documentation here.
At this point, you should be able to run the following code:
from unstructured.partition.pdf import partition_pdf
elements = partition_pdf(filename="example-docs/layout-parser-paper-fast.pGood Data = Good AI
As companies look to gain a sustained competitive edge, leveraging proprietary data within AI workflows is increasingly crucial. Over the past two years, we've collaborated with leading enterprises and developers to provide GenAI-ready data for diverse AI applications—from enterprise search to customer service agents. Moving from prototypes to production demands robust, scalable, and secure tools that businesses can rely on for their critical data tasks. With this goal in mind, we've focused on enhancing our developer experience and improving the performance of our commercial API, including achieving SOC 2 Type 2 certification. Throughout this journey, the importance of high-quality data for successful GenAI projects has been clear, and we're dedicated to simplifying the process of achieving this standard.
Improved Transformation Performance
Our Unstructured Serverless API integrates next-generation document transformation models that outperform our open-source models across several key metrics:
- Achieves a 5x increase in processing throughput for PDFs
- Enhances table classification and structure detection by 70%
- Improves text accuracy by 11% and reduces word error rate by 20%
These advancements in transformation and document element classification significantly enhance LLM-enabled workflows in three crucial areas:
- Simplified data cleaning by removing unwanted elements like headers, footers, or images.
- Enhanced utilization of advanced chunking strategies, such as segmenting documents by specific elements like titles.
- Improved retrieval efficiency through metadata filtering to highlight the most relevant data during queries.
Beyond AI-native capabilities, we've bolstered our transformation pipelines with traditional preprocessing techniques, including hand-crafted parsers, regular expressions, Python libraries, and more. This comprehensive approach ensures our solution is not only the fastest and most efficient but also the most cost-effective in the market.
Creating Your First Project:
Let's start with import some required library.
import os
import uuid
import base64
from unstructured.partition.pdf import partition_pdf
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.schema.messages import HumanMessage, SystemMessage
from langchain.schema.document import Document
from langchain_openai import OpenAIEmbeddings
from langchain_postgres.vectorstores import PGVector
Imports:
os: Provides functions for interacting with the operating system.uuid: Generates UUIDs (Universally Unique Identifiers).base64: Provides functions for encoding and decoding data as base64.from unstructured.partition.pdf import partition_pdf: Likely imports a functionpartition_pdffrom a custom or third-party module for partitioning PDF documents.- Various imports related to the
langchainandlangchain_openailibraries, which are likely custom libraries or wrappers around OpenAI's services (ChatOpenAI,LLMChain,PromptTemplate,OpenAIEmbeddings), PostgreSQL (PGVector)
from dotenv import load_dotenv
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
POSTGRES_URL_EMBEDDINDS=os.getenv("POSTGRES_URL_EMBEDDINDS")
Environment Variables:
load_dotenv(): Loads environment variables from a.envfile into the script's environment.openai_api_key,POSTGRES_URL_EMBEDDINDS,PINECONE_API_KEY: Retrieves API keys or URLs from environment variables (OPENAI_API_KEY,POSTGRES_URL_EMBEDDINDS,PINECONE_API_KEY). These are typically used to authenticate and access external services like OpenAI, PostgreSQL for embeddings, and Pinecone.
root_path = os.path.abspath(os.path.join(os.path.dirname(__file__), '..'))
filename = os.path.join(root_path, "data/fy2024.pdf")
output_path = os.path.join(root_path, "images")
Paths and File Handling:
root_path: Gets the absolute path to the directory containing the script.filename: Constructs the path to a specific PDF file (fy2024.pdf) within thedatadirectory relative toroot_path.output_path: Constructs the path to animagesdirectory relative toroot_path.
openai_ef = OpenAIEmbeddings()
Initializes an instance of OpenAIEmbeddings, presumably to utilize OpenAI's embedding functionalities for natural language processing tasks.
def file_reader():
raw_pdf_elements = partition_pdf(
filename=filename,
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=3000,
new_after_n_chars=2500,
extract_image_block_output_dir=output_path,
)
return raw_pdf_elements
This file_reader function reads elements from a PDF file specified by filename using the partition_pdf function. Here's a breakdown of its functionality:
- Reads a PDF file (
filename) and partitions it into elements based on the parameters provided. - Parameters:
filename: Path to the PDF file (fy2024.pdfin this case).extract_images_in_pdf: Boolean flag indicating whether to extract images from the PDF.infer_table_structure: Boolean flag to infer table structures from the PDF.chunking_strategy: Specifies how to chunk the returned elements. Here, it's set to"by_title", which suggests partitioning based on titles within the document.max_characters: Limits the maximum number of characters per chunk to 3000.new_after_n_chars: Specifies when to create a new chunk after 2500 characters.extract_image_block_output_dir: Directory path where extracted image blocks from the PDF will be saved (output_path/images).
raw_pdf_elements=file_reader()
The function returns raw_pdf_elements, which likely contains the structured elements extracted from the PDF based on the specified parameters.
def text_insert(raw_pdf_elements):
summary_prompt = """ Summarize the following {element_type}:{element} """
prompt=PromptTemplate.from_template(summary_prompt)
llm=ChatOpenAI(model="gpt-4o", openai_api_key = openai_api_key, max_tokens=1024)
runnable = prompt | llm
for e in raw_pdf_elements:
if 'CompositeElement' in repr(e):
text_elements.append(e.text)
summary = runnable.invoke({'element_type': 'text', 'element': e})
text_summaries.append(summary.content)
elif 'Table' in repr(e):
table_elements.append(e.text)
summary = runnable.invoke({'element_type': 'table', 'element': e})
table_summaries.append(summary.content)
Lists for Storage:
text_elements: Will store text elements extracted from the PDF.text_summaries: Will store summaries generated for text elements.table_elements: Will store table elements extracted from the PDF.table_summaries: Will store summaries generated for table elements.
Function Definition text_insert(raw_pdf_elements):
- Summary Prompt: Defines a template (
summary_prompt) for summarizing elements. It uses{element_type}and{element}placeholders to format the summary prompt. - Initializing Libraries:
PromptTemplate.from_template(summary_prompt): Initializes a prompt template for generating summaries based on the defined template.ChatOpenAI(model="gpt-4o", openai_api_key=openai_api_key, max_tokens=1024): Initializes an instance ofChatOpenAIwith the GPT-4o model and an API key for OpenAI, allowing interaction with OpenAI's language model.
Processing Elements:
- Iterates over
raw_pdf_elements. - Checks if an element is of type
'CompositeElement'(likely text) or'Table'. - If it's text (
'CompositeElement'), it appends the text content (e.text) totext_elementsand generates a summary using the defined prompt template. The summary is then appended totext_summaries. - If it's a table, it similarly appends the table content (
e.text) totable_elementsand generates a summary for tables, appending it totable_summaries.
text_insert(raw_pdf_elements)
After calling text_insert(raw_pdf_elements), text_elements, text_summaries, table_elements, and table_summaries will contain the processed text and table elements along with their respective summaries.
image_elements = []
image_summaries = []
def image_insert():
def encode_image(image_path):
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode('utf-8')
def summarize_image(encoded_image):
prompt = [
SystemMessage(content="You are a bot that is good at analyzing images."),
HumanMessage(content=[
{
"type": "text",
"text": "Describe the contents of this image."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
},
},
])
]
response = ChatOpenAI(model="gpt-4-vision-preview", openai_api_key=openai_api_key, max_tokens=1024).invoke(prompt)
return response.content
for i in os.listdir(output_path):
if i.endswith(('.png', '.jpg', '.jpeg')):
image_path = os.path.join(output_path, i)
encoded_image = encode_image(image_path)
image_elements.append(encoded_image)
summary = summarize_image(encoded_image)
image_summaries.append(summary)
The image_insert function is designed to process images located in the output_path directory and generate descriptions (summaries) for each image using an AI model. Here’s an explanation of what each part of the function does based on the provided code:
- Nested Functions:
encode_image(image_path): Opens an image file (image_path) in binary mode, reads its content, encodes it in base64 format, and returns the encoded string as a UTF-8 decoded string. This function facilitates converting images into a format that can be used within prompts for AI models.summarize_image(encoded_image): Takes an encoded image (in base64 format) as input and generates a summary description using an AI model. It constructs a prompt containing a system message indicating the bot's capability to analyze images and a human message containing the image encoded in base64 within a data URL format (data:image/jpeg;base64,{encoded_image}). It then invokes an AI model (ChatOpenAIwithgpt-4-vision-preview) using this prompt to generate the image description.
- Main Functionality:
- Iteration Over Files:
- Iterates through each file (
i) in the directory specified byoutput_path. - Checks if the file ends with a valid image extension (
.png,.jpg,.jpeg).
- Iterates through each file (
- Processing Each Image:
- Constructs the full path to the image file (
image_path). - Encodes the image using
encode_image(image_path)and stores the encoded image inimage_elements. - Generates a summary description for the image using
summarize_image(encoded_image)and stores the summary inimage_summaries.
- Constructs the full path to the image file (
- Iteration Over Files:
- Output:
- After calling
image_insert(),image_elementswill contain base64-encoded representations of images found inoutput_path, andimage_summarieswill contain descriptions generated by the AI model for each image.
- After calling
documents = []
retrieve_contents = []
def get_docummets():
for e, s in zip(text_elements, text_summaries):
i = str(uuid.uuid4())
doc = Document(
page_content = s,
metadata = {
'id': i,
'type': 'text',
'original_content': e
}
)
retrieve_contents.append((i, e))
documents.append(doc)
print("text_element done")
for e, s in zip(table_elements, table_summaries):
doc = Document(
page_content = s,
metadata = {
'id': i,
'type': 'table',
'original_content': e
}
)
retrieve_contents.append((i, e))
documents.append(doc)
print("table_elements done")
for e, s in zip(image_elements, image_summaries):
doc = Document(
page_content = s,
metadata = {
'id': i,
'type': 'image',
'original_content': e
}
)
retrieve_contents.append((i, s))
documents.append(doc)
print("image_elements Done")
The get_documents function is intended to create Document objects for text, tables, and images based on the elements and summaries collected in previous steps. Here’s an overview of what each part of the function does based on the provided code:
- Initialization:
- Lists:
documents: Stores instances ofDocumentobjects, each representing a piece of content (text, table, or image).retrieve_contents: Stores tuples containing IDs and original contents for later reference.
- Lists:
- Processing Text Elements:
- Loop: Iterates through pairs of
text_elementsandtext_summariesusingzip(text_elements, text_summaries). - Document Creation: For each pair (
efor element,sfor summary):- Generates a unique identifier (
i) usinguuid.uuid4(). - Creates a
Documentobject (doc) with attributes:page_content: Summary (s) of the text.metadata: Dictionary containing:'id': Unique identifier (i).'type': Type of content ('text').'original_content': Original text content (e).
- Appends
(i, e)tuple toretrieve_contentsfor later retrieval. - Appends
doctodocuments.
- Generates a unique identifier (
- Loop: Iterates through pairs of
- Processing Table Elements:
- Similar Loop: Iterates through pairs of
table_elementsandtable_summaries. - Document Creation: Creates a
Documentobject (doc) similar to text processing but with'type'set to'table'. - Appends
(i, e)tuple toretrieve_contentsanddoctodocuments.
- Similar Loop: Iterates through pairs of
- Processing Image Elements:
- Loop: Iterates through pairs of
image_elementsandimage_summaries. - Document Creation: Creates a
Documentobject (doc) with'type'set to'image'. - Appends
(i, s)tuple toretrieve_contents(using summarys) anddoctodocuments.
- Loop: Iterates through pairs of
Notes:
- Each
Documentcreated here encapsulates structured information (page_contentandmetadata) about text, tables, or images extracted and summarized from various sources (likely PDF and image files). - The function ensures that each piece of content (
text,table,image) is associated with a unique identifier (i) and maintains the original content (e) along with its summary (s) for later retrieval or processing.
def add_docs_to_postgres(collection_name):
vectorstore = PGVector(embeddings=openai_ef,collection_name=collection_name,connection=POSTGRES_URL_EMBEDDINDS,use_jsonb=True,)
vectorstore.add_documents(documents)
The add_docs_to_postgres function is designed to add documents (documents) to a PostgreSQL database using a vector store (PGVector). Here’s a breakdown of what each part of the function does based on the provided code:
- Function Definition:
add_docs_to_postgres(collection_name): Takescollection_nameas an argument, which likely specifies the name of the collection or table in PostgreSQL where the documents will be stored.
- Initialization:
vectorstore: Initializes aPGVectorobject:embeddings=openai_ef: Usesopenai_ef(which presumably contains embeddings from OpenAI) for embeddings associated with the documents.collection_name=collection_name: Specifies the name of the collection or table in PostgreSQL where the documents will be stored.connection=POSTGRES_URL_EMBEDDINDS: Specifies the connection URL or details for connecting to the PostgreSQL database.use_jsonb=True: Indicates that JSONB format will be used for storing document metadata and embeddings, which is a flexible data type in PostgreSQL for storing semi-structured data.
- Adding Documents:
vectorstore.add_documents(documents): Adds the list ofdocuments(presumably instances ofDocumentobjects) to the PostgreSQL database through thevectorstore
collection_name="fy2024_chunk_3000"
add_docs_to_postgres(collection_name)
The add_docs_to_postgres function is set up to add the documents stored in the documents list to a PostgreSQL database using a vector store named PGVector. The collection_name parameter specifies the name of the collection or table within the database where these documents will be stored.
Given the provided collection_name="fy2024_chunk_3000", the function call add_docs_to_postgres(collection_name) will attempt to add the documents to a collection named "fy2024_chunk_3000" in your PostgreSQL database.
Make sure that:
- The PostgreSQL database specified by
POSTGRES_URL_EMBEDDINDS(likely stored in your environment variables) is correctly set up and accessible. - The
documentslist contains instances ofDocumentobjects or data structures compatible with thePGVectorvector store.
Testing and Evaluation
def get_context_from_vectorstore(vectorstore,user_query):
relevant_docs = vectorstore.similarity_search(user_query,k=3)
context = ""
relevant_images = []
for d in relevant_docs:
if d.metadata['type'] == 'text':
context += '[text]' + d.metadata['original_content']
elif d.metadata['type'] == 'table':
context += '[table]' + d.metadata['original_content']
elif d.metadata['type'] == 'image':
context += '[image]' + d.page_content
relevant_images.append(d.metadata['original_content'])
print(d)
return contextThis get_context_from_vectorstore function is designed to retrieve relevant documents and their context from a vector store (vectorstore) based on a user query (user_query). Here's a breakdown of what each part of the function does based on the provided code:
- Function Definition:
get_context_from_vectorstore(vectorstore, user_query): Takes two parameters:vectorstore: Represents the vector store (likelyPGVectorin your case) from which relevant documents will be retrieved.user_query: Represents the query provided by the user to search for relevant documents.
- Initialization:
relevant_docs = vectorstore.similarity_search(user_query, k=3): Performs a similarity search onvectorstoreusinguser_queryand retrieves up tok=3most relevant documents (relevant_docs).
- Processing Relevant Documents:
- Loop through
relevant_docs: Iterates through each document (d) inrelevant_docs. - Document Type Check:
- Checks the type of each document using
d.metadata['type']. - If the document is
'text', appends[text]followed by the original text content (d.metadata['original_content']) tocontext. - If the document is
'table', appends[table]followed by the original table content (d.metadata['original_content']) tocontext. - If the document is
'image', appends[image]followed by the page content (d.page_content) tocontext. Additionally, adds the original image content (d.metadata['original_content']) to therelevant_imageslist.
- Checks the type of each document using
- Loop through
Output:
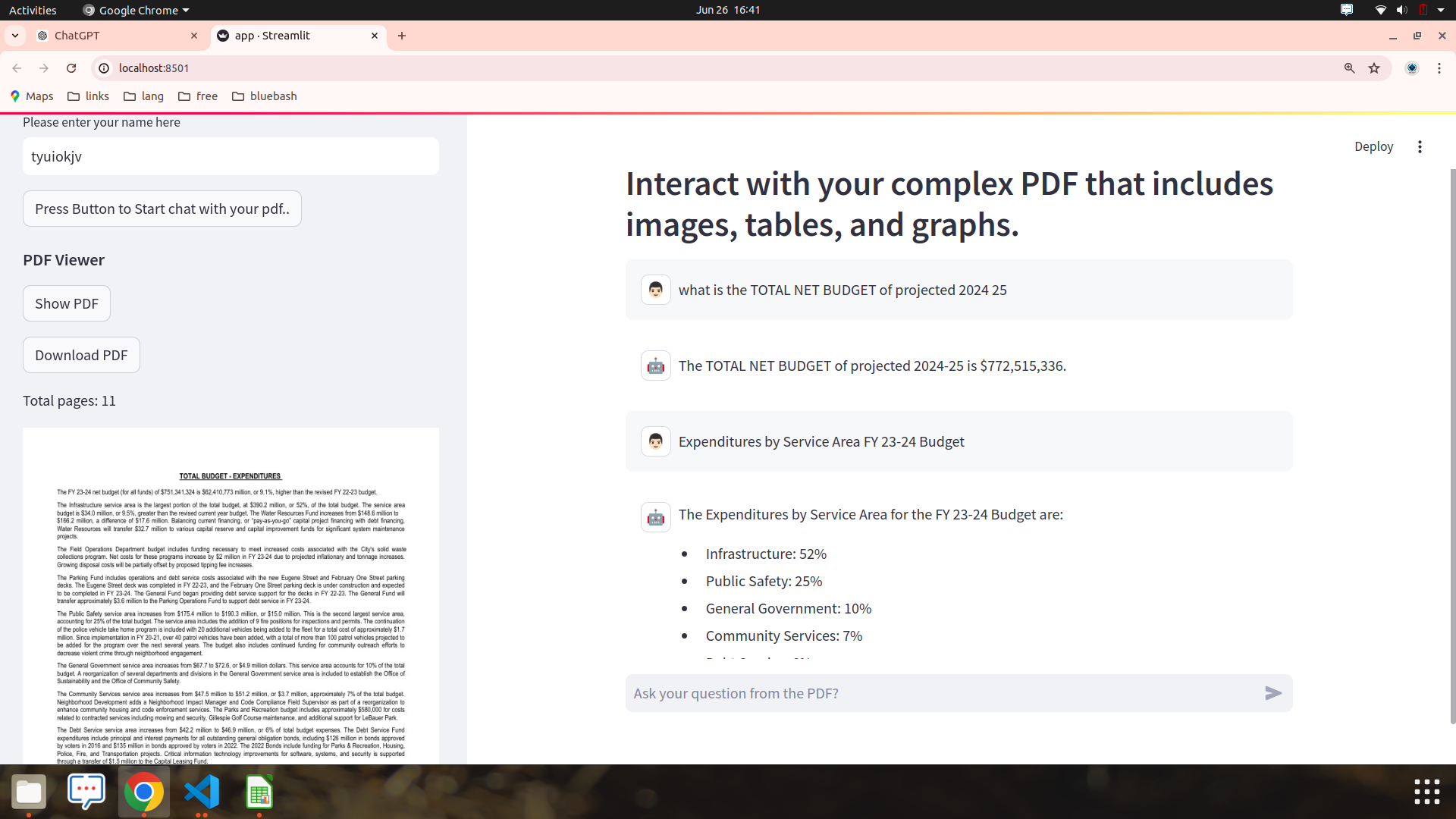
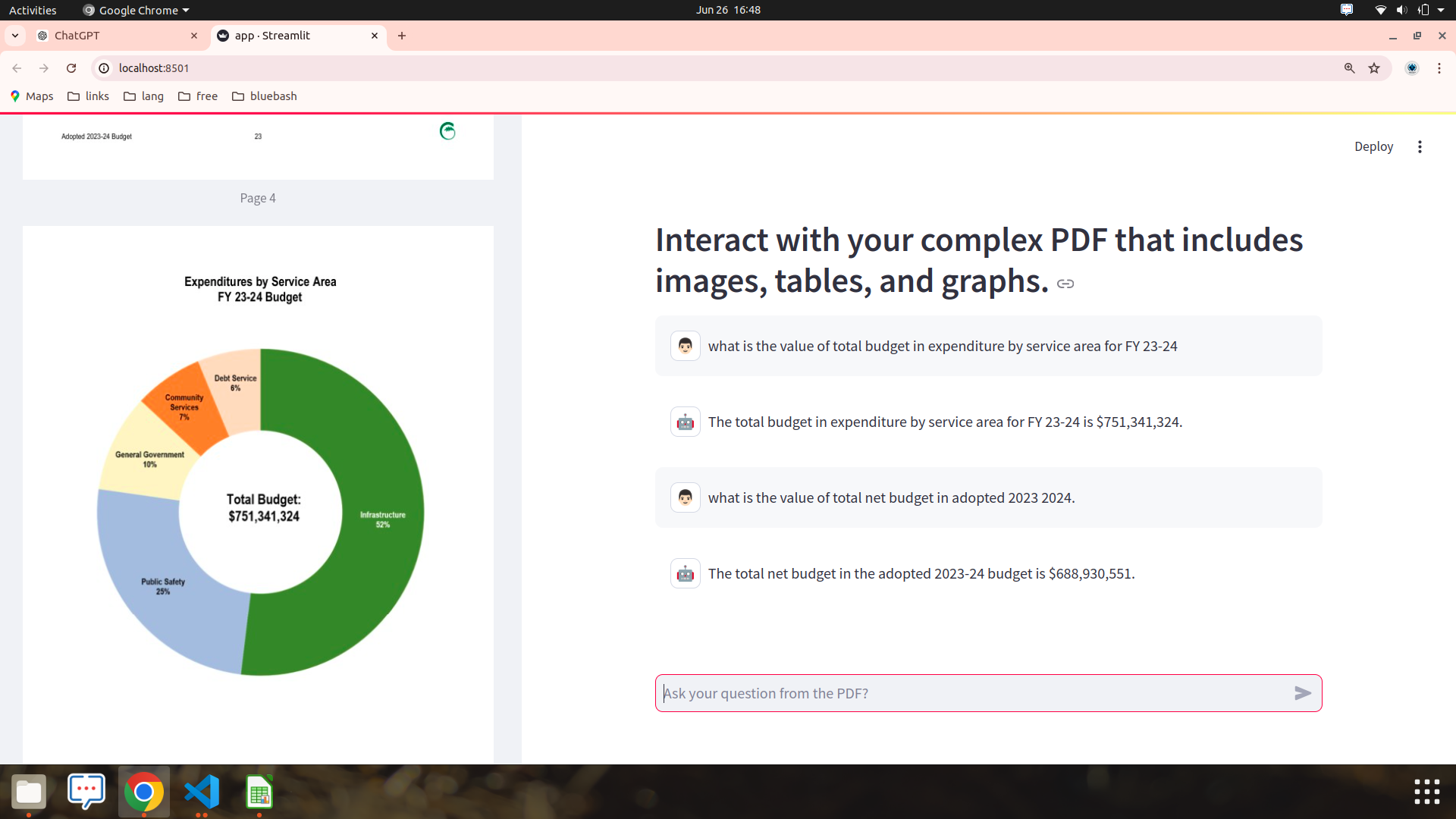
context=get_context_from_vectorstore(vectorstore,"what is the value of total net budget in adopted 2023 2024.")context: Accumulates all relevant document contexts formatted with[type]tags (e.g.,[text],[table],[image]).relevant_images: Accumulates original image contents for further processing or display.
Notes:
- Usage: This function is intended to provide context from the vector store based on a user query, categorizing and formatting relevant documents by their type (
text,table,image) for presentation or further analysis. - Integration: Ensure that the vector store (
vectorstore) is set up correctly and contains the necessary documents with associated metadata ('type','original_content',page_contentfor images) before calling this function.
Final Results:-
FAQ's
1. What does unstructured.io do?
The unstructured library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more.
2. How to install unstructured?
Install the Python SDK with pip install unstructured . You can install document specific dependencies with extras, i.e. pip install "unstructured[docx]" . To install the dependencies for all document types, use pip install "unstructured[all-docs]" .
3. What is the difference between unstructured IO and LlamaIndex?
Unstructured provides the tooling to quickly and easily preprocess data into LLM-compatible formats, and LlamaIndex provides the toolset to help connect this data with your LLM tasks.
4. What is the alternative to unstructured IO?
If you're looking for alternatives or competitors to unstructured.io, companies like Value Simplex, Tasq, Ambisense, and Tagup could indeed be considered within that realm. Each of these companies likely offers solutions or services related to data management, analytics, or similar technological domains, potentially focusing on structured, semi-structured, or unstructured data handling.
5. How is unstructured data stored?
Unstructured data is usually stored in a non-relational database like Hadoop or NoSQL and processed by unstructured data analytics programs like OpenText™ IDOL™. These databases can store and process large amounts of unstructured data. Common storage formats for unstructured data are: Text files (PDFs and emails).
6. What is an unstructured PDF file?
As mentioned, PDFs are an unstructured form of data. This is quite common. Unstructured data accounts for about 80% to 90% of data generated and collected by businesses. The challenge that this creates, however, is that the information they contain cannot be processed by software for further analysis.
7. Is PDF unstructured data?
No, PDF is not a structured data format. PDF is a document format. The contents of that document are described in a standardized way, but they could be anything. Pictures, graphs, text descriptions, tables, hyperlinks, random noise, etc.
8. What are the types of unstructured IO documents?
The Unstructured.io Team provides libraries with open-source components for pre-processing text documents such as PDFs, HTML and Word Documents. These components are packaged as bricks 🧱, which provide users the building blocks they need to build pipelines targeted at the documents they care about.
9. How to read an unstructured PDF in Python?
Firstly, we import the fitz module of the PyMuPDF library and pandas library. Then the object of the PDF file is created and stored in doc and the 1st page of the PDF is stored on page1. Using the PyMuPDF library to extract data from PDF with Python, the page. get_text() method extracts all the words from page 1.
10. What is an example of unstructured data?
Multimedia content: Digital photos, audio, and video files are all unstructured. Complicating matters, multimedia can come in multiple format files, produced through various means. For instance, a photo can be TIFF, JPEG, GIF, PNG, or RAW, each with their own characteristics.