


Elevate Your AI Game with HuggingFace Transformers: A Definitive Guide

The field of natural language processing and machine learning has been transformed by transformers, thanks to their cutting-edge capabilities. The Hugging Face Transformers library, widely embraced as an open-source resource, offers convenient access to an extensive array of pre-trained models catering to tasks like text classification, named entity recognition, question answering, language modeling, summarization, translation, and beyond.
Benefits of Using Transformers
- Reduced Compute Costs: By utilizing pre-trained models, users can significantly reduce the time and resources required to train a model from scratch, leading to cost savings.
- Environmental Impact: Pre-trained models also help in lowering the carbon footprint associated with training large-scale models, making them more environmentally friendly.
- Time Efficiency: With access to a diverse set of pre-trained models, developers can quickly prototype and deploy solutions without spending extensive time on training.
The Hugging Face Transformers library supports various tasks across different modalities, including:
- Natural Language Processing: Within the realm of Natural Language Processing, transformers are proficient in text classification, named entity recognition, question answering, language modeling, summarization, translation, multiple choice, and text generation.
- Computer Vision: Image classification, object detection, and segmentation.
- Audio: Automatic speech recognition and audio classification.
Exploring Transformers in the Hub
With over 25,000 transformers models available in the Hub, users can easily find models for various tasks such as question-answering, summarization, text classification, text generation, token-classification, automatic speech recognition, and more. The Hugging Face community continuously updates and maintains these models to ensure high performance and reliability.
Using a Pipeline for Sentiment Analysis with Hugging Face Transformers
This guide demonstrates how to use a Hugging Face pipeline for sentiment analysis on text data. Pipelines offer a high-level interface, simplifying the process of using pre-trained models for common tasks.
1. Install Required Libraries:
The first step is to install the necessary libraries using pip:
$ pip install transformers This command will install the Hugging Face Transformers library, which provides the functionality for pipelines and working with pre-trained models.
2. Import the Library:
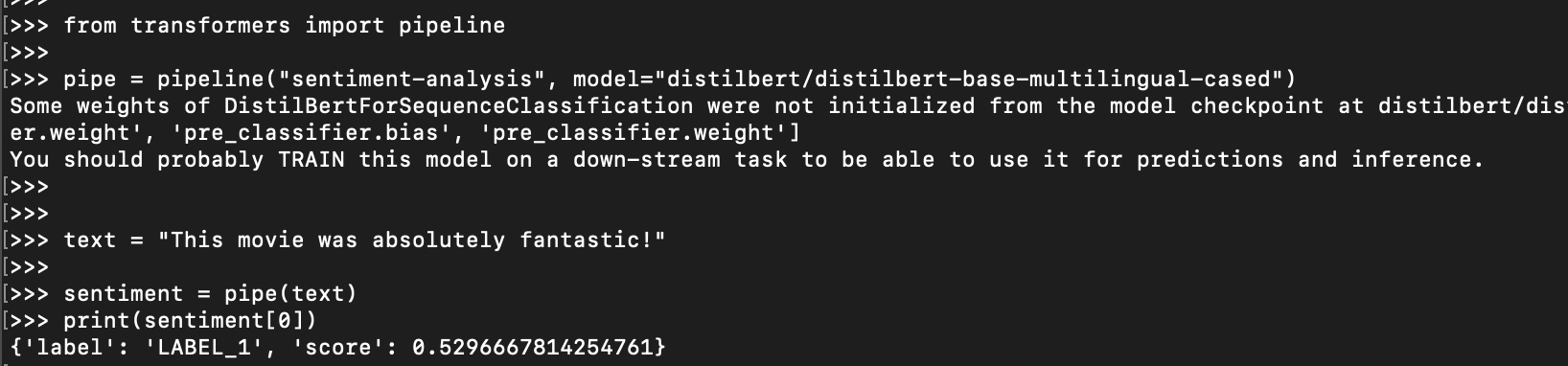
from transformers import pipeline3. Define the Task and Model:
- We'll use the
"sentiment-analysis"task for sentiment analysis. - We'll leverage the pre-trained model
"distilbert/distilbert-base-multilingual-cased"for this task.
# Define the task and model
pipe = pipeline("sentiment-analysis", model="distilbert/distilbert-base-multilingual-cased")
4. Prepare Your Text Data:
The pipeline typically expects plain text strings as input.
# Sample text for sentiment analysis
text = "This movie was absolutely fantastic!"
5. Use the Pipeline for Prediction:
Here's the magic! The pipe object acts as a wrapper, handling all the complexities behind the scenes:
# Perform sentiment analysis using the pipeline
sentiment = pipe(text)6. Interpret the Output:
The pipeline returns a list, with the first element containing the sentiment analysis results for your input text. This element will be a dictionary with sentiment information.
print(sentiment[0]) # Print the sentiment analysis results
# Example Output (may vary):
# {'label': 'POSITIVE', 'score': 0.9998}Explanation of the Output:
The output dictionary typically contains keys like:
label: This indicates the predicted sentiment (e.g., "POSITIVE", "NEGATIVE", "NEUTRAL").score(optional): This represents the confidence score associated with the predicted label (a value between 0 and 1).
Advanced Tips and Tricks for Optimizing Performance
As you delve deeper into the world of Hugging Face Transformers and explore the vast capabilities of pre-trained models, it becomes essential to optimize performance for efficient machine learning projects. Here are some advanced tips and tricks to enhance the performance of your models:
1. Efficient Training Techniques
Utilizing methods and tools for efficient training on a single GPU or multiple GPUs can significantly speed up the training process. Techniques such as Fully Sharded Data Parallel, DeepSpeed, and distributed CPU training can help maximize the utilization of resources and improve training efficiency.
2. Hyperparameter Search using Trainer API
Optimizing hyperparameters is crucial for achieving optimal model performance. By leveraging the Trainer API in Hugging Face Transformers, developers can efficiently search for the best hyperparameters for their models, leading to improved accuracy and faster convergence.
3. Optimizing Inference
Efficient inference is key to deploying models in production environments. By exploring techniques for CPU and GPU inference, instantiating big models, and leveraging XLA Integration for TensorFlow Models, developers can ensure fast and reliable model predictions.
4. Contribution and Collaboration
Active involvement in the Hugging Face community and contributions to the library can enhance the performance of existing models and foster innovation in artificial intelligence. By following guidelines on how to contribute to Transformers, add new models, and convert models to TensorFlow, developers can actively participate in advancing the capabilities of the library.
Examples of Implementing Transformers Library
Transformers have become an indispensable tool in the world of artificial intelligence, offering a wide range of applications and functionalities. Let's explore some examples of how you can implement the Hugging Face Transformers library in your projects:
Text Classification with BERT
One common use case of the Transformers library is text classification, where you can utilize pre-trained models like BERT to classify text into different categories or labels. By fine-tuning a BERT model on a specific dataset, you can achieve high accuracy in tasks such as sentiment analysis, topic classification, and spam detection.
Named Entity Recognition with GPT-3
Named Entity Recognition (NER) is another task that can benefit from the power of pre-trained models like GPT-3. By leveraging the Transformers library, you can extract entities such as names, locations, organizations, and more from unstructured text data with high precision and recall.
Question Answering with T5
The Transformers library also offers models like T5 that excel in question-answering tasks. By inputting a question and a context, you can utilize T5 to generate accurate answers, making it ideal for applications like chatbots, search engines, and virtual assistants.
Language Modeling with GPT-2
GPT-2 is a powerful language model available in the Transformers library that can be used for various language modeling tasks. By predicting the next word in a sequence, GPT-2 can generate coherent and contextually relevant text, making it suitable for tasks like text generation and dialogue systems.
Summarization with BART
For tasks requiring text summarization, models like BART in the Transformers library can be incredibly useful. By inputting a long piece of text, BART can generate concise and informative summaries, making it valuable for applications like news aggregation and document summarization.
These are just a few examples of how you can leverage the power of the Hugging Face Transformers library in your machine learning projects. By exploring the capabilities of pre-trained models and experimenting with different tasks, you can unlock new possibilities in natural language processing and artificial intelligence.
FAQ's
1. What are Hugging Face Transformers?
Hugging Face Transformers is a popular open-source library built on top of the core Transformer architecture. It provides easy access to a vast collection of pre-trained models for various natural language processing (NLP) tasks like text classification, question answering, summarization, translation, and more. These pre-trained models can significantly reduce development time and resources compared to training models from scratch.
2. What is the difference between GPT and Transformers?
- Transformers: This is a general neural network architecture designed for various NLP tasks. It excels at capturing relationships between words in a sentence and has become the foundation for many state-of-the-art NLP models.
- GPT (Generative Pre-trained Transformer): This is a specific family of pre-trained models based on the Transformer architecture. GPT models are known for their text generation capabilities, like GPT-2 and GPT-3.
Hugging Face Transformers offers access to many pre-trained models, including GPT models like GPT-2 and GPT-3, but also extends to other architectures like BERT, T5, and more.
3. Is Hugging Face Transformers free?
Yes, Hugging Face Transformers is a free and open-source library. You can utilize it for both personal and commercial projects without any licensing fees. However, some pre-trained models within the library might have specific usage restrictions defined by their creators. It's always best to check the individual model's documentation for details.
4. What are Transformers used for in NLP?
Transformers find application in a diverse array of NLP tasks, including:
- Text Classification: Categorizing text into different classes (e.g., sentiment analysis, spam detection)
- Named Entity Recognition (NER): Identifying and extracting named entities like persons, locations, organizations from text data.
- Question Answering (QA): Answering questions based on a given context or passage.
- Language Modeling: Predicting the next word in a sequence, used for text generation and dialogue systems.
- Summarization: Creating concise summaries of longer pieces of text.
- Machine Translation: Translating text from one language to another.
- Text Generation: Creating new text content like poems, code, scripts, etc.
5. Is Hugging Face a Python library?
Yes, Hugging Face Transformers is primarily a Python library, although it can be used with other frameworks like TensorFlow.js for browser-based applications.
6. Who created the Transformers library?
While the Transformers architecture itself has multiple contributors, the Hugging Face Transformers library was developed and is maintained by the Hugging Face community, a collective of researchers and developers passionate about NLP advancements.
7. What is the Hugging Face transformers format?
Hugging Face Transformers utilizes a specific format for storing pre-trained models. These models are typically saved in a format like PyTorch or TensorFlow checkpoints, allowing them to be loaded and used within those frameworks.
8. Can Hugging Face models be used commercially?
Yes, most models in Hugging Face Transformers can be used for commercial purposes. However, it's crucial to check the individual model's license for any specific restrictions. Some models might require attribution or have limitations on commercial deployment.
9. What is the use of Hugging Face Transformers?
Hugging Face Transformers simplifies NLP development by providing pre-trained models for various tasks. This allows developers to focus on building applications without needing to train large models from scratch. It's a valuable tool for tasks like:
- Building chatbots and virtual assistants
- Implementing sentiment analysis for social media monitoring
- Creating text summarization tools
- Developing machine translation applications
- Generating creative text formats like poems or code
10. Is Hugging Face free?
The Hugging Face platform itself is free to use, including the Transformers library. However, some cloud-based services offered by Hugging Face might have associated costs depending on the usage level.


